Structured concurrency in Python with AnyIO
How to improve your spaghetti asyncio code
17 August 2020
By now you might be familiar with the term 'structured concurrency'. It's a way to write concurrent programs that's easier than manually taking care of the lifespan of concurrent tasks. The best overview is Notes on structured concurrency by Nathaniel Smith (or his video if you prefer).
This post is about AnyIO, a Python library providing structured concurrency primitives on top of asyncio. This is important because your project is probably dependent on an asyncio-based library (e.g. Starlette or asyncpg) if you are building a non-trivial production system, so you sadly can't use Trio.
The current state of async Python
Python has three well-known concurrency libraries built around the async/await syntax: asyncio, Curio, and Trio.
The first, asyncio, was designed by Guido van Rossum and is included in the Python standard library. Since it's the default, the overwhelming majority of async applications and libraries are written with asyncio. It has, however, received mixed reviews12.
The second and third are attempts to improve on asyncio, by David Beazley and Nathaniel Smith respectively. Neither of them has an ecosystem to match asyncio, but Trio, in particular, has very effectively demonstrated the benefits of structured concurrency. Indeed, the Python core team appears to have been persuaded that asyncio should move in that direction since at least as far back as 20173. But as of today, asyncio's progress has been slow. Python's async ecosystem is therefore in a strange place, as described by Nathaniel on Stack Overflow:
If you need to ship something to production next week, then you should use asyncio (or Twisted or Tornado or gevent, which are even more mature). They have large ecosystems, other people have used them in production before you, and they're not going anywhere. [...]
If you want to ship something to production a year from now... then I'm not sure what to tell you. Python concurrency is in flux. Trio has many advantages at the design level, but is that enough to overcome asyncio's head start? Will asyncio being in the standard library be an advantage, or a disadvantage?
That was written two years ago and still holds true today. For those of us looking for structured concurrency in Python, it turns out there's another solution, described next.
AnyIO to the rescue
The AnyIO library by Alex Grönholm describes itself as follows:
an asynchronous compatibility API that allows applications and libraries written against it to run unmodified on asyncio, curio and trio.
So you might assume it's only useful if you want to write code that is agnostic between those backends. I think that's a pretty niche scenario: it applies if you are, for example, creating a new database driver and you want it to be used as widely as possible4.
However, it's much more likely that you are a consumer of an existing database driver, one that is almost certainly written against asyncio (e.g. asyncpg, aredis). If you continue reading the AnyIO docs, you learn that:
You can even use it together with native libraries from your selected backend in applications. Doing this in libraries is not advisable however since it limits the usefulness of your library.
This is the most important part. You can in fact use it directly with libraries written for asyncio. In other words:
AnyIO is an implementation of structured concurrency for asyncio.
The author doesn't recommend using it like this if you're writing a library because it runs counter to the ostensible point of AnyIO: your code will not be backend-agnostic. I'm sympathetic to his point, since if everyone builds on top of AnyIO, then the whole community benefits from greater flexibility.
But if you're a pragmatic engineer building production systems, you can ignore that advice. You can use AnyIO as an enhancement to asyncio, when creating libraries as well as applications. Alex has modelled AnyIO's API after Trio, so this is a significant improvement.
An example: graceful task shutdown
I recently released Runnel, a distributed stream processing library for Python built on top of Redis Streams. It is dependent on aredis, an asyncio Redis driver and I want it to be usable by applications with other asyncio dependencies.
I built the first prototype directly with asyncio, but working with its gather and wait primitives was very frustrating. Neither of them will cancel other tasks when one fails5. And building correct cancellation semantics on top is non-trivial to say the least: just look at the AnyIO implementation.
The main problem was cleaning up resources during a graceful program shutdown. In Runnel, workers hold locks implemented in Redis for partitions of an event stream. They should be released when a worker exits, so that others can quickly acquire them and continue to work through the backlog of events. Here's the most basic clean up example in AnyIO:
import anyio
async def task(n):
await anyio.sleep(n)
async def main():
try:
async with anyio.create_task_group() as tg:
await tg.spawn(task, 1)
await tg.spawn(task, 2)
finally:
# e.g. release locks
print('cleanup')
anyio.run(main)
This program will run for 2 seconds before running the finally block. In a
more realistic scenario, the tasks might run forever until one of them raises an
exception. Using AnyIO, the remaining tasks will be cancelled and the finally
block will run before control flow continues beyond the TaskGroup's scope.
(See here for more information about this API.)
This is more or less the fundamental insight of structured concurrency:
constraining task/thread lifespans (e.g. via Python's async with block)
greatly improves your code's simplicity and correctness.
Managing tasks and their clean up code only gets harder as your program increases in complexity: imagine multiple nested groups of tasks, being spawned from each other, some with specific timeouts or cancellation criteria. For example, in Runnel the task graph looks approximately like this:
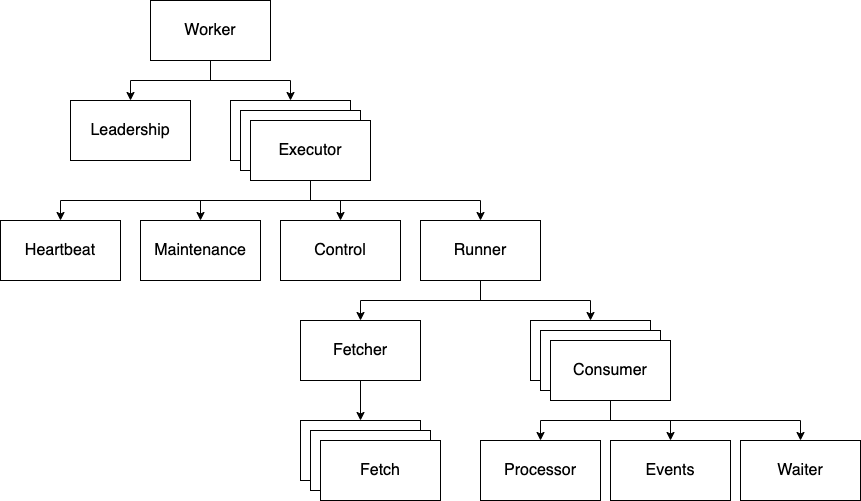
If you're interested in this architecture, check out the Runnel docs. For our purposes, what matters is that each box is an independent asyncio task running forever or until a specific event or timeout occurs. Failures in tasks should be handled by their parent: normally by propagating the exception after cancelling all siblings and cleaning up. Sometimes restarting the task is appropriate. Implementing this scheme became much easier when I switched from native asyncio to the AnyIO abstractions. (See, for example, the task groups here, here and here.)
In addition to the task groups described above, AnyIO also provides other primitives to replace the native asyncio ones if you want to benefit from structured concurrency's cancellation semantics:
- Synchronisation primitives (locks, events, conditions)
- Streams (similar to queues)
- Timeouts (e.g.
move_on_after,fail_after) - ... and more
Caveats
The caveats are as follows (from here):
You can only use “native” libraries for the backend you’re running, so you cannot, for example, use a library written for trio together with a library written for asyncio.
Tasks spawned by these “native” libraries on backends other than trio are not subject to the cancellation rules enforced by AnyIO
Threads spawned outside of AnyIO cannot use run_async_from_thread() to call asynchronous code
The second one is particularly important and is the main problem with using AnyIO in the manner I'm suggesting. If the asyncio libraries you rely on create their own tasks, then all bets are off. AnyIO cannot manage their lifespan: it does not monkey patch asyncio to retrofit structured concurrency. Each library is responsible for cleaning up its tasks. This may or may not be a deal-breaker for your use case.
I found that aredis, for example, failed to propagate cancellation to its internal asyncio task when waiting for pubsub messages. They would live beyond the AnyIO cancel scope in which they are created, so I decided to avoid pubsub. Unfortunately you will need to test the third-party code you depend on to decide whether it is safe for your use case.
Summary
Asyncio is hard to use because it doesn't support structured concurrency, but has very wide library support. Trio is easy to use, but it's not the community default so its library ecosystem cannot compete.
This post presents an alternative: use AnyIO on top of asyncio for the best of both worlds.
-
https://lucumr.pocoo.org/2016/10/30/i-dont-understand-asyncio/ ↩
-
https://web.archive.org/web/20171206113205/https://veriny.tf/asyncio-a-dumpster-fire-of-bad-design/ ↩
-
See here, where the lead maintainer of asyncio wants to implement TaskGroups (like Trio's nurseries). ↩
-
Compare Sans-I/O, which is a different solution to the same problem. ↩
-
See https://bugs.python.org/issue31452, where this issue was thought to be a 'serious bug' before being rejected for backwards compatibility. Note also that Yury Selivanov suggests that TaskGroups (as found in AnyIO) are the solution. ↩